
Lo barato sale caro
Una encuesta bien hecha es un instrumento muy caro. Nadie en su sano juicio gastará una pequeña fortuna para hacer una encuesta con cuestionarios mal diseñados y muestras mal seleccionadas. Cuando leemos sobre resultados de una encuesta, ¿vale la pena creerles? Una encuesta es un ejercicio de eficiencia feroz para obtener la mejor información por el menor costo posible, pero hay cosas en las que no es posible escatimar.
Si lo que buscamos es información fidedigna de una población específica necesitamos, como mínimo: un cuestionario bien diseñado, un mecanismo de selección que permita tener resultados estadísticamente robustos y una estrategia de análisis adecuada para la información recabada y (muy importante) para los intereses de los usuarios finales. Cuidar cada uno de estos detalles es fundamental para garantizar que la información que recibimos describa a la población de interés con la mayor precisión posible.
La confiabilidad de los resultados depende –en gran medida– del método con el que fueron recabados. A continuación discuto algunos de estos puntos, así como sus consecuencias para la confianza que podemos tener en las encuestas.
Preguntas mal hechas (o, de plano, encuestas que no lo son)
Hacer bien una pregunta para una encuesta no es tan fácil como parece y los errores en las preguntas suelen ser una señal de que el ejercicio no es legítimo –le echaron tan pocas ganas que ni siquiera pensaron bien la pregunta. Los errores al diseñar mal una pregunta son algo obvios. Por ejemplo, la presentación de las opciones de respuesta debe ser balanceada, sin favorecer una u otra opción. Asumiendo que la pregunta esté bien hecha, también es importante conocer las preguntas anteriores que el encuestado había respondido. Un cuestionario hecho sin cuidado (o con malicia) puede hacer una larga lista de preguntas sobre todas las obras y logros de un candidato para luego preguntarle si votaría por él.
Conocer los cuestionarios completos no es tan sencillo porque suelen ser confidenciales y sólo tienen acceso a ellos los encuestadores (y sus clientes, cuando están interesados). Afortunadamente, por ley, las encuestas que reportan de forma pública sus estimaciones de intención de voto deben depositar sus cuestionarios y bases de datos en el repositorio del Instituto Nacional Electoral (ine), lo que da un grado significativo de transparencia y confianza a sus resultados. Si el cuestionario y la base de datos no son públicos, la credibilidad de los resultados es significativamente menor.
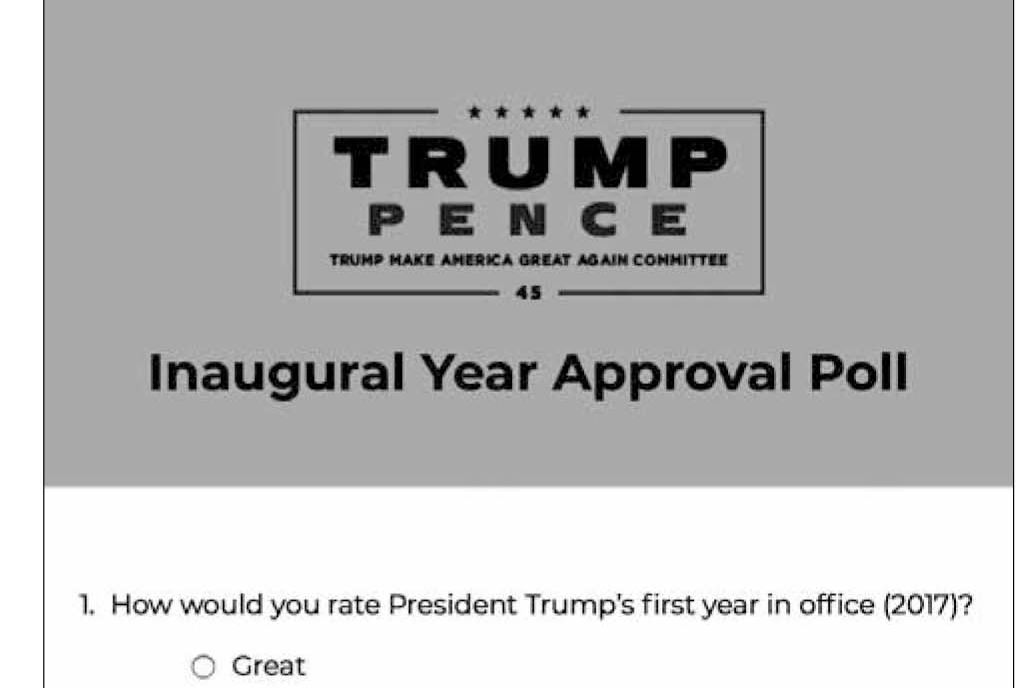
Una pregunta hecha sin cuidado es una señal grave de incompetencia o, llanamente, de malicia. Es posible que lo que estamos sufriendo sencillamente no es una encuesta, sino lo contrario: un intento de influir –y no de estudiar– nuestras opiniones y comportamiento. Un ejemplo de esto son las llamadas push polls, en las que una persona es contactada bajo el engaño de encuestarlo para solamente leerle información, vagamente formulada como pregunta, que favorece o ataca a algún candidato. Otro ejemplo puede ser una falsa encuesta que sólo sirve para recopilar datos personales que más tarde serán usados con otro fin. En mis clases sobre metodología de encuestas suelo mostrar mi colección de preguntas mal hechas.1 Mi ejemplo favorito es la encuesta que circuló tras el primer aniversario en el gobierno del presidente Trump.2
Esta supuesta encuesta contenía la siguiente joya:
Quien escribió estas preguntas tenía tan pocas ganas de recopilar información valiosa que ni siquiera agregó las opciones de respuesta balanceadas para Trump –no es posible responder que lo hizo mal (y el «otro» no da opción a registrarlo). Resulta que para responder a la encuesta era necesario dar información personal –como teléfono y correo electrónico– que la organización que promovía la encuesta más tarde usaría para recaudar fondos para la campaña. Una pregunta claramente sesgada es una señal inequívoca de una intención distinta a recopilar información.
Encuestados mal seleccionados
El gran superpoder que tienen las encuestas es permitirnos describir una población solamente con un conjunto más pequeño y manejable de casos, esto es, con una muestra. Esto hace todo mucho más rápido y barato. El costo de este superpoder es la variación ineludible que viene de trabajar con una muestra, porque los resultados no serán idénticos si obtenemos una muestra distinta.
Los resultados que tenemos a la mano contienen una cantidad no trivial de incertidumbre muestral que sólo podemos reducir al obtener muestras más grandes (pero no eliminar del todo sin hacer un censo a toda la población). Esta variación es ineludible, pero es el precio que tenemos que pagar por estudiar una población grande con solo algunos de sus elementos.
El secreto está en la forma como los elementos de una muestra son seleccionados. El ejemplo más sencillo es en una muestra aleatoria simple: básicamente una lotería en la que todos tienen la misma probabilidad de ganar el premio de responder a nuestras preguntas. Aún esto es incosteable para una encuesta a la población del país, por lo que las muestras son seleccionadas aleatoriamente a partir de grupos (por ejemplo, municipios dentro de estados) que a su vez fueron seleccionados aleatoriamente.
Pero no es suficiente que la muestra sea aleatoria. También debe ser probabilística, esto eso, debemos conocer lo suficientemente bien a la población que estudiamos para saber cuál es la probabilidad de cada entrevistado de resultar seleccionado en una muestra particular. Esto significa, para una muestra compleja, por ejemplo, que debemos conocer la probabilidad de seleccionar un municipio dentro de un estado, la de seleccionar un área en particular dentro del municipio, una manzana dentro de esta área, la vivienda dentro de la manzana y al entrevistado entre todos quienes viven ahí. Sólo conociendo todas estas probabilidades podemos inferir correctamente el valor que nos interesa de la población –ya no de la muestra– y la incertidumbre que le está asociada.
Hago este repaso para resaltar que la selección aleatoria de los encuestados es imprescindible para garantizar que los resultados que obtengamos de una muestra se acerquen lo suficiente a lo que sucede en la población. La selección aleatoria es la mejor forma de garantizar que la muestra no fue escogida de forma que los resultados sean afectados sistemáticamente por el mecanismo de selección (evitaría los errores de encuestar a mis amigos o a la gente que sale de una estación del metro un día por la tarde). Cualquier muestra que provenga de un procedimiento no aleatorio es útil solamente si es la única forma de alcanzar a una población muy específica. Y, aún así, no permitirá hablar de todo este grupo, sino sólo de quienes participaron.
La selección aleatoria es imprescindible para estudiar cualquier otra población, especialmente para estudiar las intenciones de voto de todos los ciudadanos del país. Al leer una encuesta debemos buscar en su nota metodológica evidencia de que los encuestados fueron seleccionados con un mecanismo aleatorio. Cualquier encuesta reportada con el mínimo de transparencia deberá incluir información detallada sobre esto. Si no la tiene, queda claro que quienes publican esos números le están echando aún menos ganas.
Es importante notar que es posible hacer estimaciones a partir de muestras no probabilísticas, esto es, cuyas probabilidades de selección no son conocidas. Pero estas muestras significan un problema técnico aún mayor porque requieren ser de gran tamaño y de modelos estadísticos sofisticados para acercar los resultados «a representar» la composición de la población de interés. Un ejemplo muy notable es el estudio de Wang et al.,3 en el que predijeron el resultado de la elección presidencial en Estados Unidos usando una muestra de 350 mil usuarios del juego de video Xbox (un grupo mucho más joven, masculino y educado que la población del país). Su muestra no era probabilística –no conocían las probabilidades de selección de los participantes, relativas a la población total del país– pero su tamaño permitió a Wang y sus coautores estimar la proporción de votos por Obama y Romney con gran precisión.
Lograron hacer esta predicción porque, al menos en Estados Unidos, usar un Xbox no está correlacionado con las preferencias electorales de los jugadores una vez que el efecto de varias de sus características demográficas ha sido tomado en cuenta. Pero es notorio que lograr una predicción de este tipo requiere tres cosas importantes y potencialmente muy caras: un proceso de recolección de los datos que no influya en lo que queremos estudiar, una muestra de gran tamaño y la pericia técnica para procesar los datos correctamente. Por lo tanto, cualquier encuesta que no esté basada en una muestra aleatoria y probabilística, que no tenga serias demostraciones de cuidado y que explique claramente la forma de recopilación y procesamiento de los datos debe ser tratada como altamente sospechosa.
La vida social de una encuesta
Una encuesta es una herramienta de investigación muy útil para conocer a una población. En sí misma –y si está bien hecha– no tiene por qué beneficiar a un candidato o a un grupo sobre otro. Pero es importante notar que no hay una sola forma de hacer bien una encuesta (aunque hay muchas formas de hacerla mal). Hay un rango amplio de variaciones metodológicas que producen resultados apropiados y cada casa encuestadora que hace bien su trabajo desarrolla, con el paso de los años, su propia forma de hacerlo. Cuando están bien hechas, las variaciones entre los resultados de distintas encuestas se deben, por lo tanto, a la eterna incertidumbre muestral y a la receta preferida por cada casa encuestadora.
La consistencia en el método es importante porque durante una campaña electoral, cuando el estado de la competencia puede cambiar de forma rápida e impredecible, cambios en la metodología pueden resultar en cambios en los resultados que, a su vez, pueden ser confundidos con (o ser mal interpretados como) eventos asociados a la elección. La utilidad estratégica de las encuestas electorales disminuye en consecuencia.
Aunque idealmente mínimo, el sesgo que imprime el estilo de cada casa encuestadora será sistemático. Al menos en una elección de alcance nacional hay muchas casas encuestadoras publicando resultados. Para entender mejor el estado del electorado durante una campaña resulta mucho mejor agregar los resultados de todas las encuestas disponibles y, con ello, acumular toda la información que contienen en una sola medición de la intención de voto. Este tipo de modelos fueron puestos de moda por Nate Silver antes de la elección de Barack Obama en 2008. En México, seis modelos de agregación fueron publicados rumbo a la elección presidencial de 2018 (entre ellos, Michelle Torres –de la Universidad de Rice– y yo colaboramos en el modelo de Bloomberg).
Cada uno de estos modelos es el resultado de diversos procesos estadísticos que toman como insumo los resultados de cada encuesta, de las tendencias que los anteceden y de la casa encuestadora que los produjo; aunque cada uno los procesa de forma distinta. En conjunto, estos modelos presentaron una imagen consistente del electorado al momento en que las encuestas fueron levantadas y, más cerca de la elección, generaron una predicción de los resultados. Como ilustración, reproduzco la tabla con las predicciones finales de estos modelos elaborada por Javier Márquez para Oraculus.mx:
Estos modelos de agregación son importantes porque dan una idea de lo que todas las encuestas están observando al mismo tiempo, mitigando el sesgo de casa que cada una pueda inducir. Además, son importantes para evaluar encuestas de organizaciones nuevas. Si sus resultados son cercanos a la tendencia medida por los modelos de agregación es posible inferir que el método que utilizó da resultados similares al resto. Por otro lado, si el resultado que promueve la encuesta está alejado de las tendencias agregadas, bien puede ser que el método pudo ser utilizado de forma correcta pero tener muy mala suerte. Pero puede indicar también que los resultados no son del todo confiables.
Una sola medición muy lejana al resto puede ser un accidente, pero una medición consistentemente alejada puede perder credibilidad rápidamente. Esto es veneno puro para cualquier encuestador que cuide su reputación como investigador social responsable (a menos que sólo quiera vivir repartiendo números alegres por una sola elección, en cuyo caso lo que reparte no son resultados de encuestas).
Para terminar, habiendo repasado muchos de los motivos por los cuales uno no debe confiar en una encuesta, creo imprescindible discutir un motivo muy importante por el que uno no debe desconfiar de ellas: porque sus resultados no son los que queremos. Esto es distinto a desconfiar de una encuesta porque tiene resultados alejados del resto. Me refiero a la desconfianza que generan las encuestas cuando una (o muchas) dicen, por ejemplo, que va a ganar el candidato de la competencia. Esta desconfianza por los resultados que no nos gustan es un fenómeno psicológico bastante generalizado: solemos aceptar con mayor facilidad la evidencia que es consistente con lo que ya creemos (o nos conviene creer). Y esto sucede también con los resultados de las encuestas.4
Si bien no debemos confiar ciegamente en los resultados de una encuesta sin antes verificar, en la medida de lo posible, su probidad metodológica, tampoco debemos desconfiar de una encuesta bien hecha sólo porque no dice lo que queremos. Es por eso que, al hacer una encuesta, es necesario saber cómo hacer una encuesta. No sólo porque cada detalle errado le resta credibilidad a sus resultados, sino también porque entendiendo mejor el método es posible confiar en lo que dicen a pesar de que no nos guste. Este es un consejo útil para consumidores de resultados de encuestas publicadas en los medios, pero también para tomadores de decisiones cuyas acciones dependen del estado de la opinión pública. Siempre es mejor investigar más y actuar en consecuencia que descontar la evidencia en mano porque es inconveniente.
1 Colecciono historias de horror en @salvador_vma
2Véase:https://www.newsweek.com/trump-fake-poll-doesnt- let-americans-disapprove-white-house-764804.
Consultado el 09 de junio de 2020.
3 Wang, W., Rothschild, D., Goel, S, & Gelman, A. (2015). Forecasting elections with non-representative polls. International Journal of Forecasting, vol. 31.
4 Ozan, K., Pasek, J. & Traugott, M. (2017). Motivated Reasoning and the Perceived Credibility of Public Opinion Polls. Public Opinion Quarterly, vol. 81, n. 2.














